Week 10
Experimentation
Installing and running MALLET according to The Programming Historian tutorial went smoothly overall. The biggest challenge proved to be remembering to change the \ to / since I have a Mac.
Because the scroll bar was not visible, I also initially missed that this line of code continues:


I did not type the entire line the first time and got an error message.
I used MALLET to topic model the 400 movie review text files that I previously loaded into Voyant. It took only a couple of seconds to make the .mallet file and ten seconds to complete the train-topics operation. I was impressed by the speed of the process of going from text files to results. I realize that the number of files was small in comparison to the huge amounts that need to be processed in full-scale topic modeling projects, and I did not have to clean the data before getting started; still, it is encouraging to get results that quickly when experimenting with a new tool.
Keys 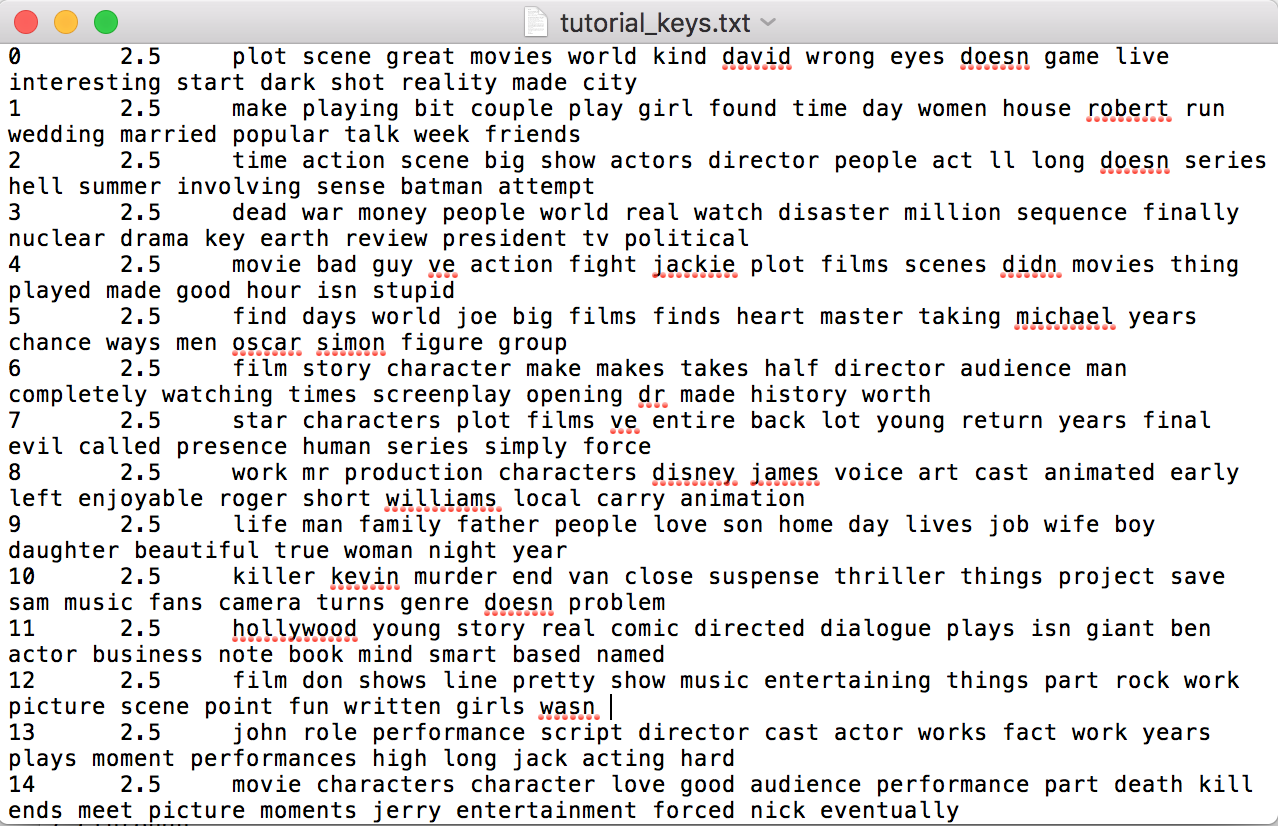
I was less encouraged when I got to the part in the tutorial that explained that I would need to work back and forth between the Keys and Composition files to see which movie review files had topics in common.
Composition 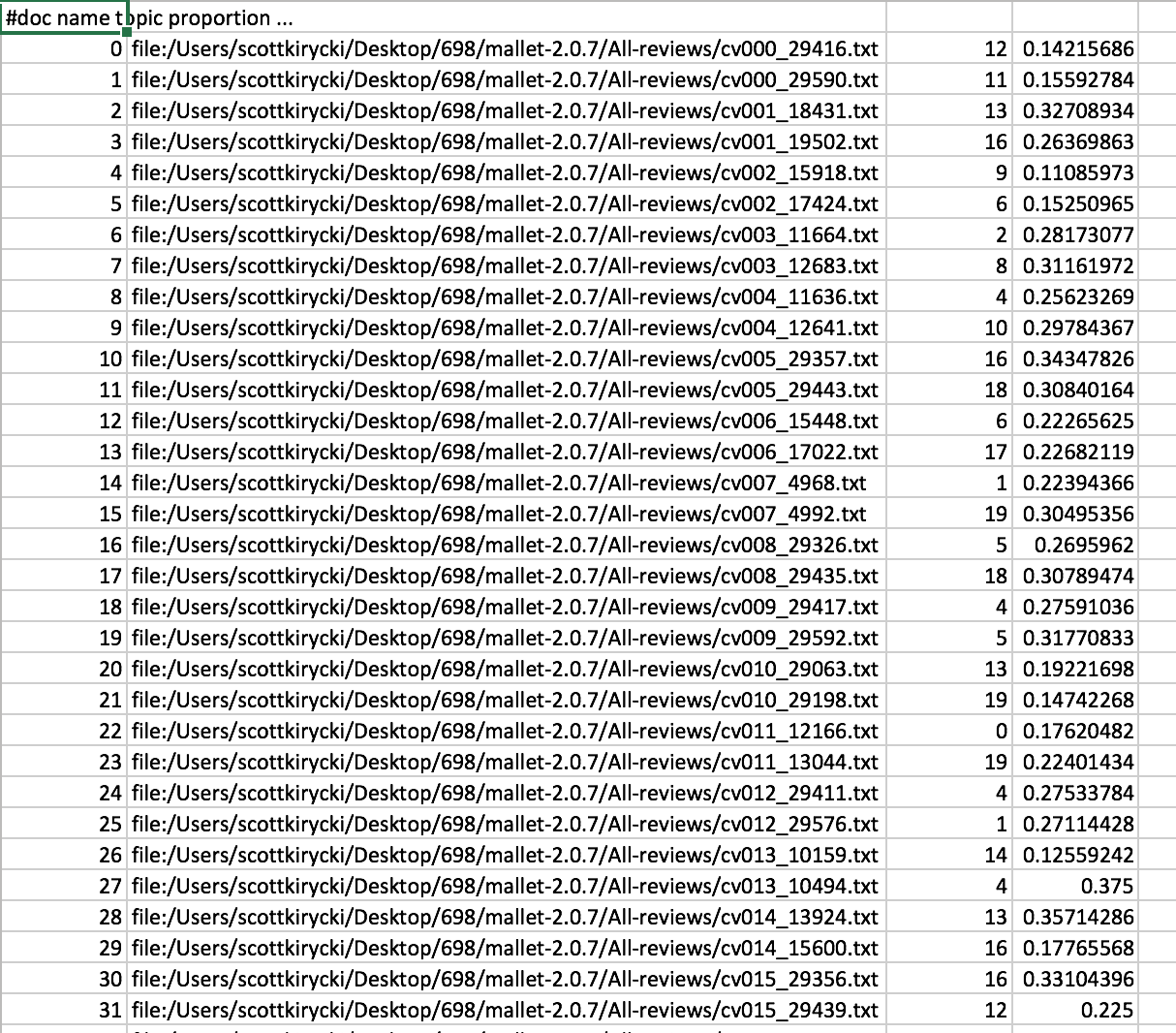
This was an example of a lesson that has come up several times in the course of HIST 698: the output of a tool is just the beginning, and the output may need to be imported into another tool for further work. I have seen this approach of using small standalone software modules that do one thing well and can be linked to other modules successfully employed in archival processing software, and it is intriguing to see that it also occurs elsewhere in the humanities.
Application
Docs 0 and 31 both had topic 12 (film don shows line pretty show music entertaining things part rock work picture scene point fun written girls wasn) as their principal topic. This suggests that the reviews of the movies Soul Survivors and Rock Star may have a connection that is not readily apparent. While this insight is not world-shaking, I did get a good idea of the topic modeling concept from my experiment with MALLET, and I thought of a possible use for topic modeling in my field of archives. I see topic modeling as having potential for getting a handle on the increasingly vast amounts of born-digital data that are starting to come into archives. Perhaps a workflow could be developed that incorporates topic modeling to fairly quickly generate topics to go into a basic finding aid. Such a finding aid would help researchers decide if the data was relevant to their area of interest or not.
Comparison
For comparison, I also loaded the 400 movie reviews into Overview. The Word Cloud feature reminds me of what I saw in Voyant. (Indeed, there appears to be much overlap and complementariness in text mining and topic modeling.)

The interface of Overview, with features such as Word Co-occurrence, is appealing for clicking around and seeing what topics surface.
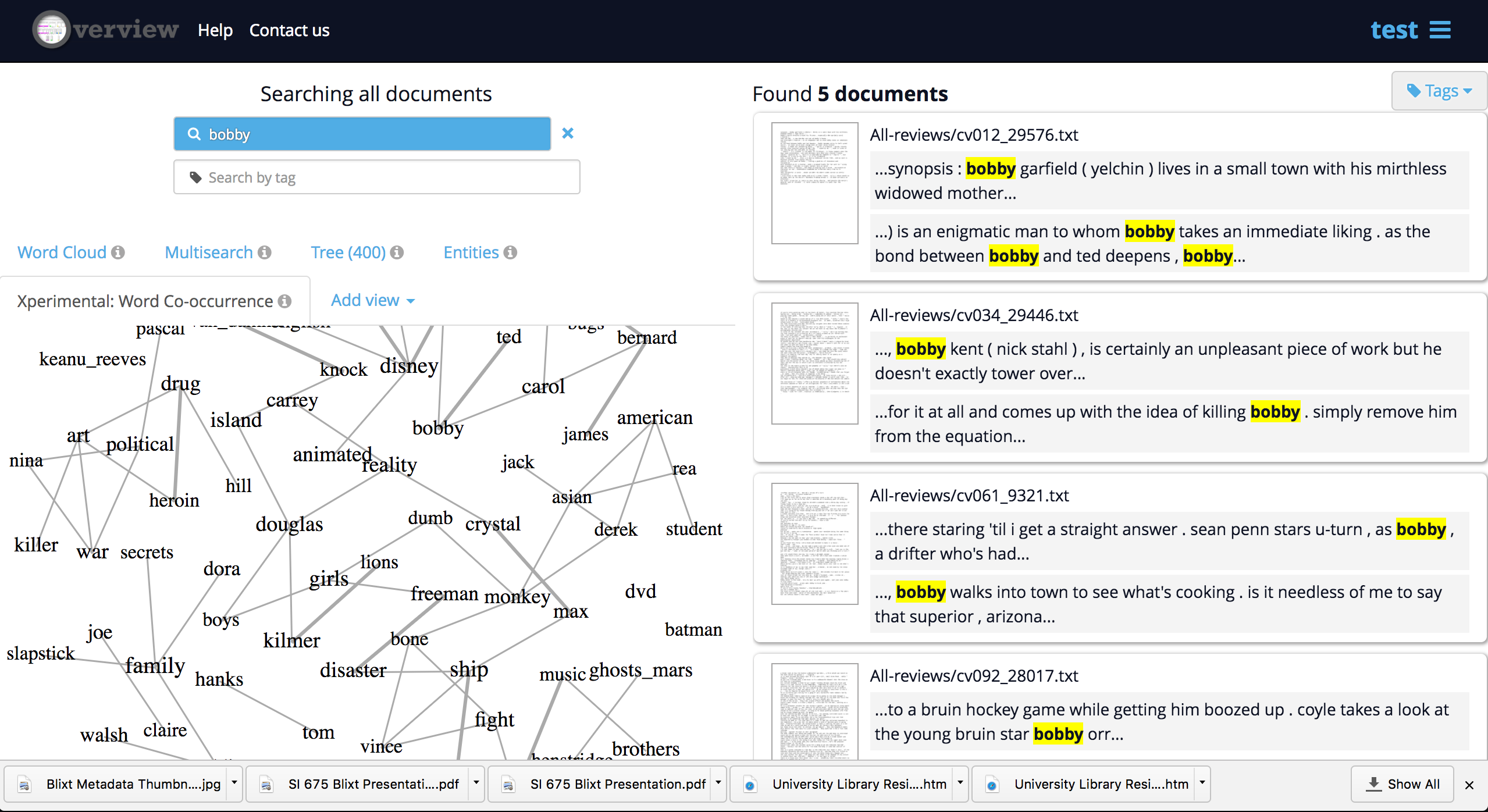
Overview thus strikes me as a tool well-suited for starting to explore a large volume of unfamiliar texts and looking at what topics emerge through serendipity. It would also be useful as a quicker way than MALLET to seek a new perspective on a familiar corpus.
Concerns
Topic modeling presents a dilemma for me as someone who lacks a heavy stats background. If I made what I took to be a significant discovery through topic modeling, I would be reluctant to claim it without being sure of the statistics behind the results. From the readings, it appears (to this stats novice) that the statistics at the heart of topic modeling are very involved. Would it be worth the time to get a degree in stats just to build my confidence in topic modeling so I could use it in research as a digital humanist? I think not. I am, however, encouraged by Cameron Blevins’ examination of Martha Ballard’s diary that found similar results from topic modeling to those from work done by hand. Blevins shows that in one case at least, topic modeling was valid.
While it might not be possible to validate all topic models the way Blevins did, there is still the option (and necessity) of comparing the distant reading from topic modeling to a close reading of the same texts. The researcher needs to confirm that any insights from topic modeling are actually supported by the text.