Week 9
Experimentation
To experiment with Voyant, I loaded the sample corpus of movie reviews from The Programming Historian’s AntConc tutorial. The load time for the 400 documents seemed pretty speedy, and the various charts and graphs also appeared quickly.
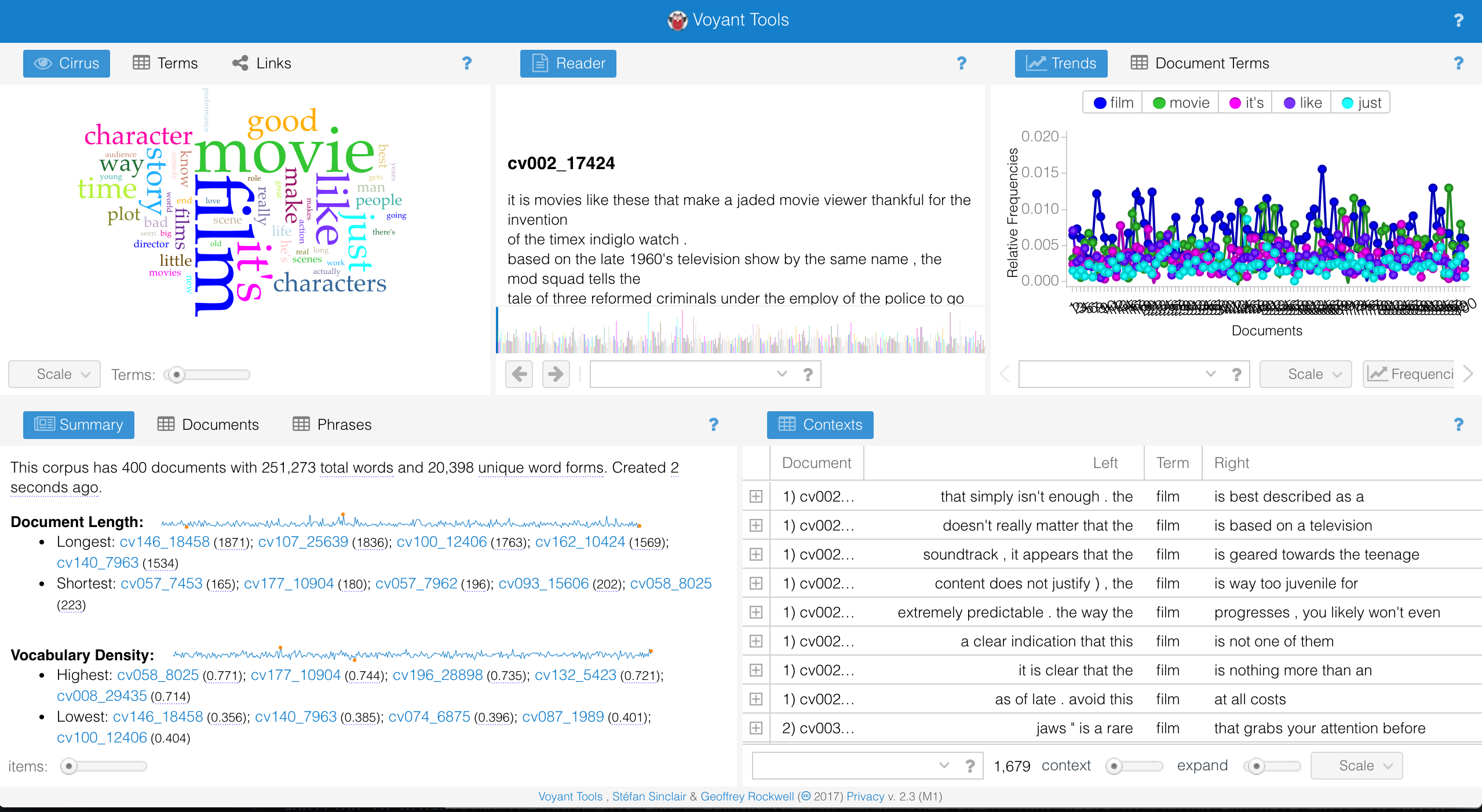
AntConc similarly presented me with interesting-looking results after minimal set up and load time. I used the browser-based emulator from Universitätsbibliothek Freiburg.
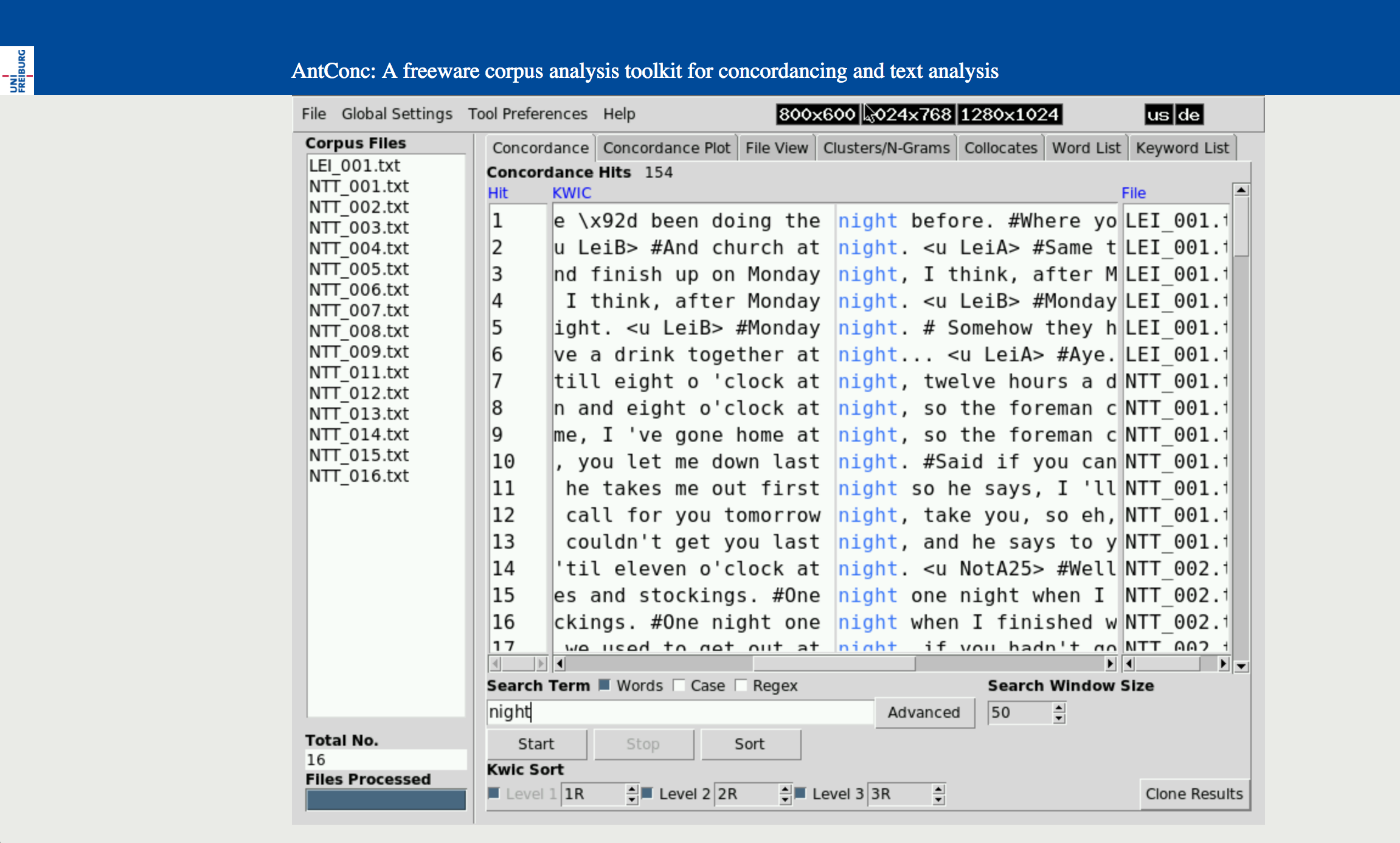
The array of analysis tools and viewing options offered by the software intimidated me at first. Part of this stemmed from my unfamiliarity with the texts I was using. If I had real research texts to process, I assume I would be familiar with the content and have some idea of what I wanted to analyze which would then lead me to the appropriate feature in the tools. To help make my thinking about text mining more concrete, I considered how it might be used in an archives setting since that is my area of study in grad school.
Application
I considered a potential application of text mining that occurred to me during a guest lecture in SI 632 - Appraisal of Archives. Tamy Guberek, a current PhD student at the University of Michigan School of Information, spoke about a project that she worked on while part of a human rights data analysis group. The group had access to 80 million pages of records from the Historical Archive of the Guatemalan National Police. The group analyzed a dataset derived from a sample of the police records to find evidence that the terms chosen by the police to report on deaths changed as policies of information control changed between 1978 and 1985 – a period in which three different military regimes held power in Guatemala. The analysis further showed the flow of information through the chain of command, and the analysis was used during later trials of regime authorities to establish that the authorities knew the level of violence that was occurring under the repressive military rule. The dataset was also used to show that documents introduced as evidence in trials were typical of the collection as a whole.
The creation of the dataset required a huge effort from the activists and archivists who worked with the collection. In addition to organizing the documents and cleaning them of mold, they spent four years of coding and data entry to build the full sample. Along with these activities, scanning of the documents began and continues to this day. In the past 13 years, 20 million of the 80 million pages have been scanned. The corpus of scanned pages seems to me to be a potential candidate for text mining.
I envision two purposes for the text mining. First, it would be an opportunity to validate the results of the earlier sampling with a larger data set. The 20 million pages could be loaded into text mining software, and then tools similar to Voyant’s Phrases and Contexts views and AntConc’s Clusters/N-Grams and Collocates tabs could be used to look at the terms that the archivists were interested in studying. Second, once the text mining process was established, it could perhaps be used to reduce or eliminate the need for manual coding and data entry in subsequent analyses.
I say “perhaps” because, after reading about text mining projects and working with the tools and tutorials, I can envision that a considerable amount of work would be necessary to prepare and clean the data for mining. Of particular concern would be how effective OCR could be given the condition issues that result from the documents at one time being left to rot in warehouses. OCR would also be problematic if a large percentage of the documents are handwritten. Finally, there might be constraints on what could be done with the tools since the documents are in Spanish, and the tools may be optimized for working with English.
Qualitative interpretation of the text mining results could also be tricky. In her lecture, Guberek described how the team needed to work with former police women who brought insider knowledge of the way the Guatemalan National Police nuanced the vocabulary that they used in their reports. As with many of the text mining projects that we discussed in class, text mining of the Police Archives would require extensive existing knowledge of the corpus on the part of those making the interpretation.
Guberek also pointed out an aspect of the documents that might challenge the qualitative interpretation of the text mining. She described the language in the documents as being crafted to distort the truth about the violence that was occurring in Guatemala and even to conceal it through silence. It would be interesting to see if text mining could clarify the distortions or fill in the silence.